SETUP · Configure each channel
5 ways to store your notes — set up one at a time.
Each card below is one storage location or export method. All share one entry point: open MN on iPad / iPhone / Mac → Settings → Backup & Restore.
📁 Auto-backup to a local folder
No network · Rock-solid · No cloud quota
- Open MN → Settings → Backup & Restore
- Scroll to "Backup Location", pick "Local Folder"
- Choose where to store (on iPad, a folder in the Files app; on Mac, anywhere in Finder)
- Pick a frequency: Manual / Hourly / Every 6h / Every 12h / Daily / Weekly
Backup format: .marginbackupall. You manage the file — store it wherever you like. Nothing gets uploaded automatically.
🗄️ Auto-backup to WebDAV / NAS
Synology / self-hosted / corp WebDAV / Jianguoyun
- Settings → Backup & Restore → Backup Location → "WebDAV Server"
- Under "WEBDAV CONFIGURATION", fill in Server URL (e.g.
https://dav.example.com/), Username, Password - Tap "Test Connection" to verify it can reach the server
- Pick a frequency — MN will push backup bundles on your schedule
Supports HTTPS with self-signed certs; for Jianguoyun use an "app password" not your login password; Synology / QNAP built-in WebDAV works with the regular account.
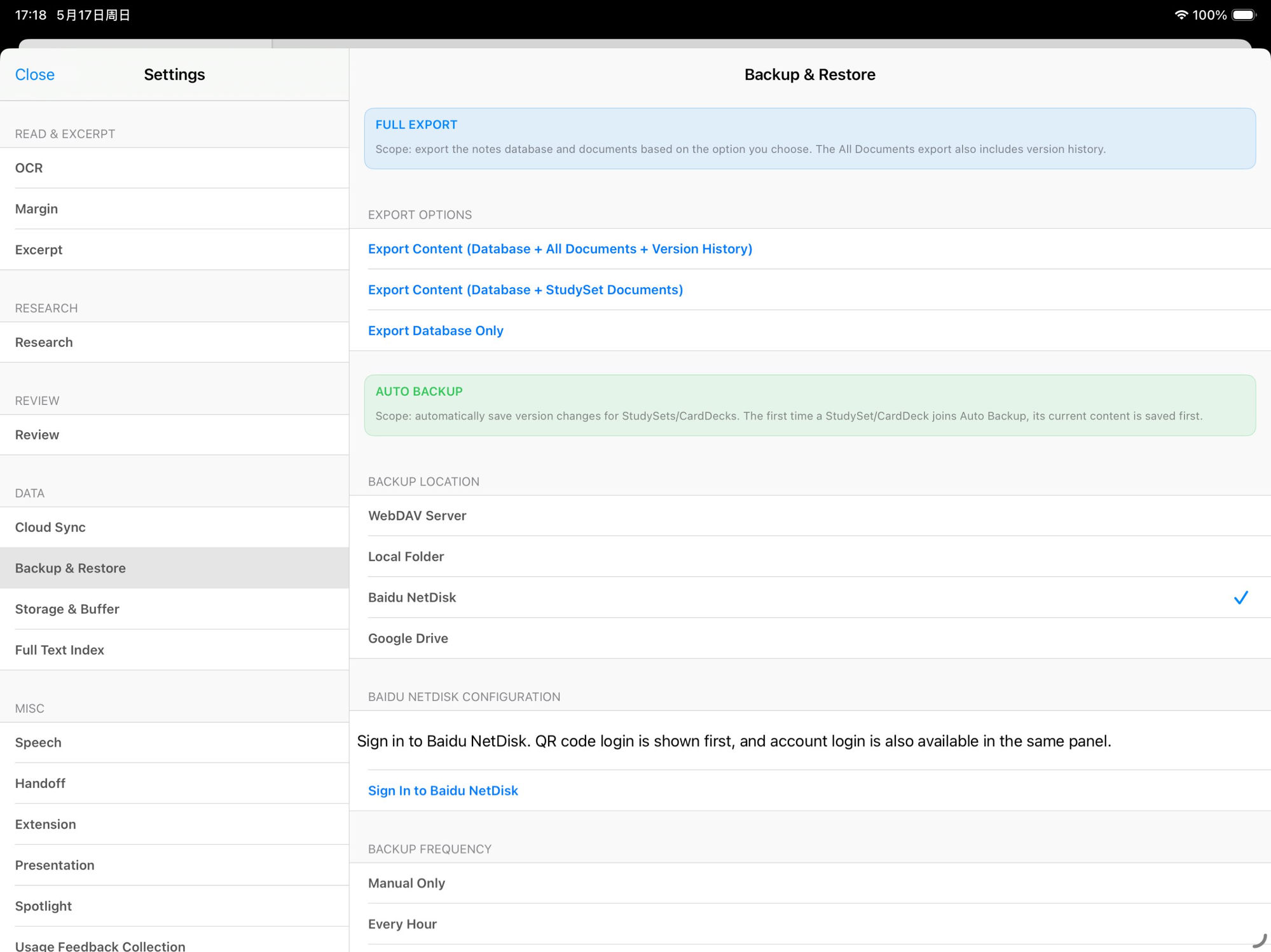
☁️ Auto-backup to Baidu NetDisk
China-region preferred · Large capacity · QR login
- Settings → Backup & Restore → Backup Location → "Baidu NetDisk"
- Tap "Sign in to Baidu NetDisk" — QR code login first (scan from the Baidu NetDisk mobile app); account / password login is available in the same panel
- After authorization, return to MN and pick a frequency
- The first run uploads the current Study Set / card deck content as a full bundle (slow); subsequent runs only push changes
Bundles are placed in a dedicated MarginNote folder in your Baidu NetDisk. Standard accounts have plenty of room for multiple full Study Set backups.
☁️ Auto-backup to Google Drive
Overseas preferred · OAuth · Cross-device access
- Settings → Backup & Restore → Backup Location → "Google Drive"
- Tap sign-in to launch Google OAuth — authorize MN to write to its dedicated folder in your Drive
- Return to MN and pick a frequency
- Requires reliable access to Google services; after first authorization the token auto-refreshes — no repeated logins
Bundle size limited by your Google Drive quota (15 GB free shared with Gmail / Photos). Consider toggling "include original PDFs / videos" — notes-only data is typically < 200 MB.
💾 Manual Full Export bundle
Long-standing · Manual · Best for migrating to a new device
- Settings → Backup & Restore → "Full Export" card at the top
- Three granularity options:
- Database + All Documents + Version History — full archive, best for moving to a new device
- Database + StudySet Documents — only PDFs tied to Study Sets, saves space
- Database Only — note metadata only, no PDFs
- Exports
MarginNoteBackup(yyyy-MM-dd-HH-mm-ss).marginbackupallto any location - Restore: install MN on new device → Settings → Backup & Restore → pick the local
.marginbackupallfile → import
This mechanism predates the MN 4.3 architecture. Auto-backup is for continuous safety; Full Export is good for occasional manual archives to an external SSD.
📌 Settings entry: MN → Settings → Backup & Restore. You can enable multiple at once — recommended: at least "Local + one cloud" — one copy you control, one copy off-site.