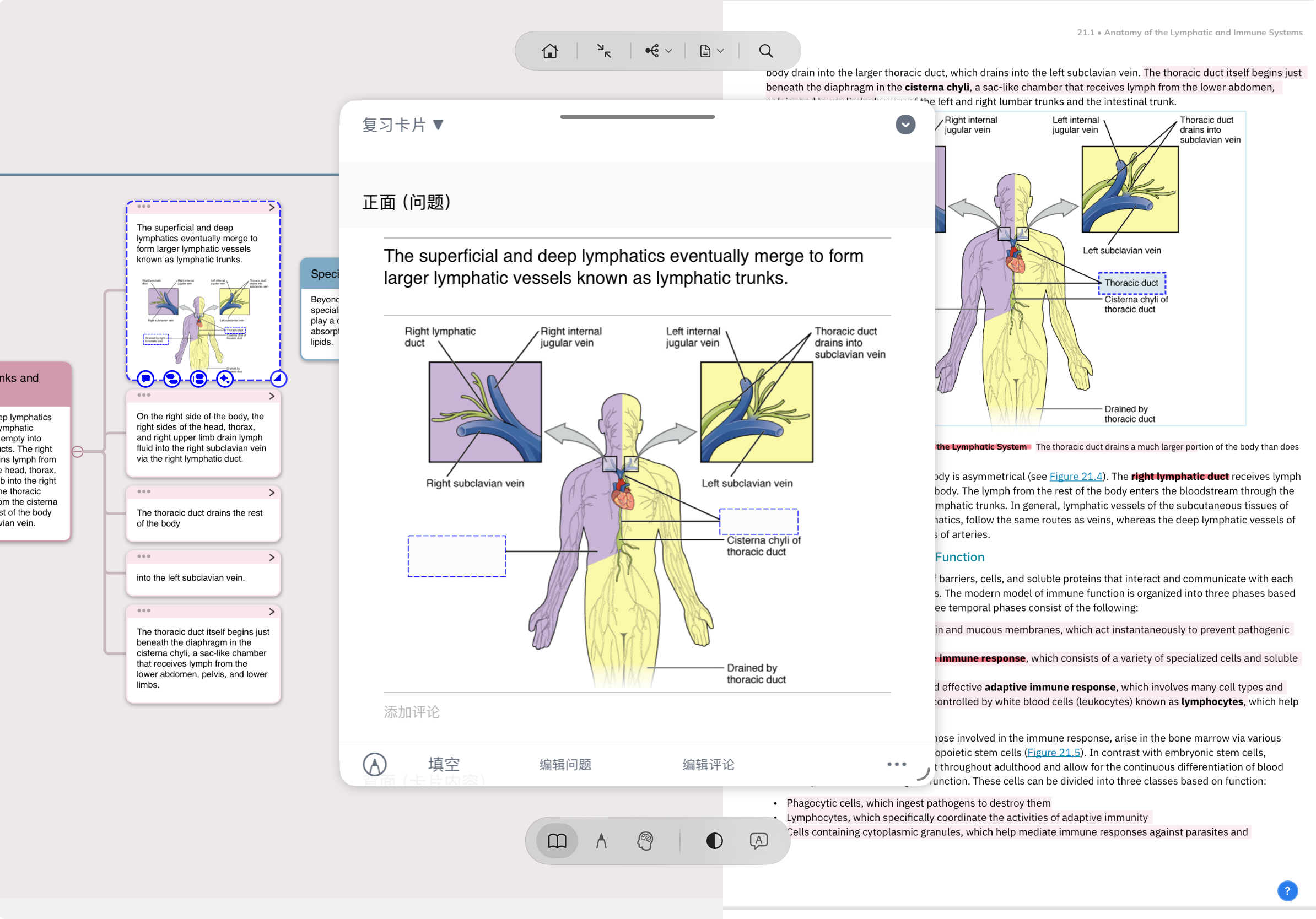
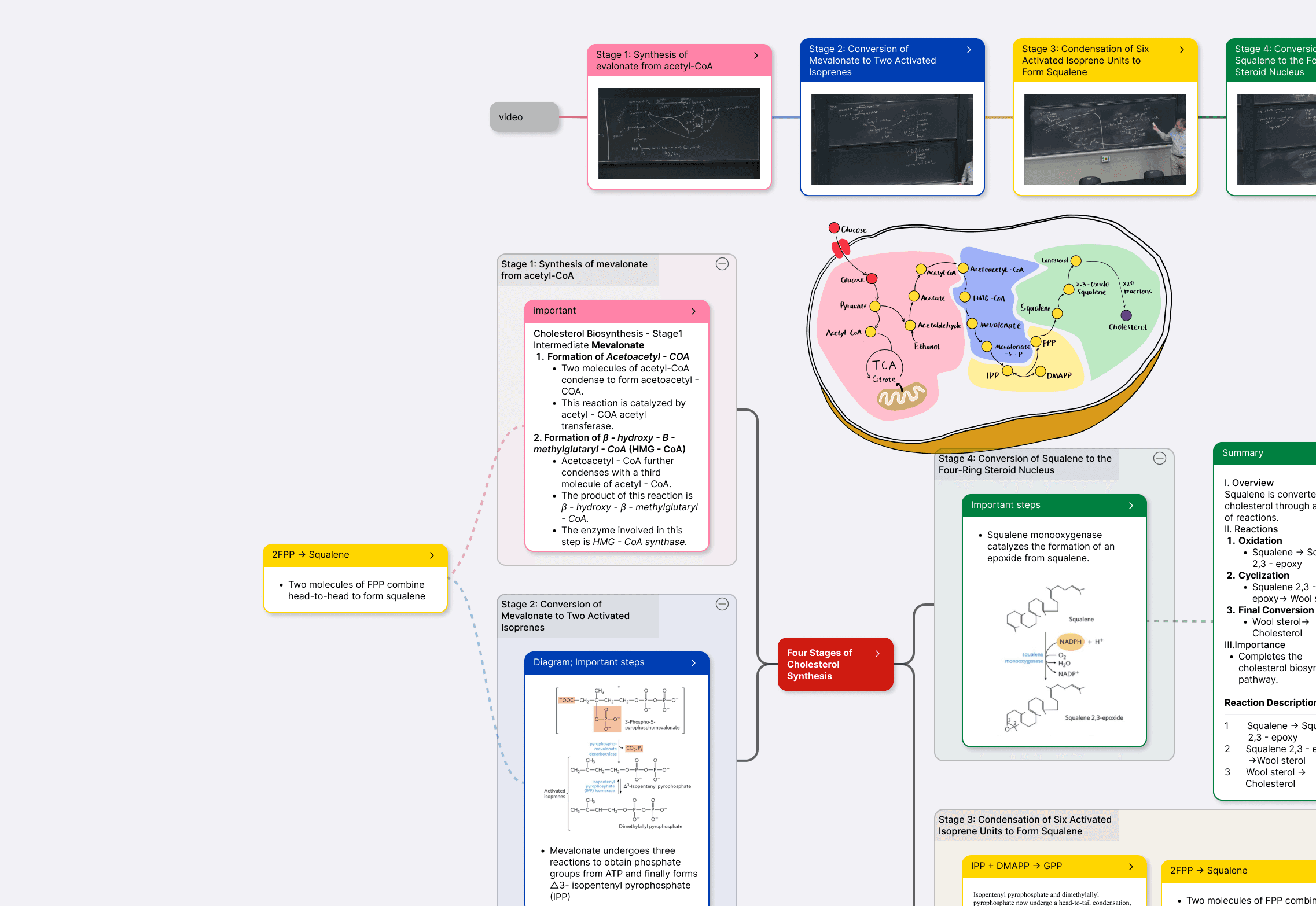
交互式 Demo · 文档 ↔ 卡片 ↔ 脑图
摘录 一次——看三处同时生效
下面是 MN 的三视图模拟:左边是文档 PDF,右边是脑图,中间是卡片轴心。点底部 4 个阶段按钮,看一张卡片如何同时是 PDF 上的高亮、脑图里的节点、可翻面的闪卡。
📄文档视图 · PDF
Robbins · Ch.12 · 心血管
心肌梗死(myocardial infarction, MI)是冠状动脉急性闭塞导致心肌缺血性坏死。
诊断三联:临床确诊基于典型胸痛 + 心电图 ST 段改变 + 心肌酶 cTnI/cTnT 升高。三者具备其二即可临床诊断。
分型上 STEMI 需紧急 PCI;NSTEMI 走 GRACE 分层。
📇卡片 · 同一原子
📭 等待摘录...
📇 #atom_001
(背面 · 注释暂无)
点击翻回正面
点击卡片翻面
🧠脑图视图 · 心血管系统
🫀 心血管系统
└─ 还没有节点 · 等待摘录
阶段 0 · 三视图各自独立——还没摘录任何内容
💡 关键不是"同步"——而是"它们本来就是同一个对象"。其他工具的"PDF + 笔记 + 卡片"是 3 个独立数据源,要靠"导出 / 导入 / 同步"维护一致。MN 这里 PDF 高亮 = 脑图节点 = 闪卡——不是三份数据互相同步,是一份数据的三种渲染。这是为什么改一处三处都自动跟着变。
真实使用中的样子